Na época, fazia sentido ter um espaço de agregação, que pudesse puxar feeds de um monte de lugar e construir contextos que dessem sentido para esses dados. Cheguei até a montar essa apresentação que levamos para o Fórum de Cultura Digital, 2009, na Cinemateca em São Paulo.
A agregação de RSS/Atom é um recurso fundamental para a experiência da web que temos hoje. Mas, tem fortes limites de estruturação dos dados e da forma como eles podem ser processados por pessoas e máquinas. Em tese, as possibilidades de remixagem desses dados são bastante primárias, pois apenas recebemos o conteúdo bruto. Qualquer processamento a partir dele, tem de ser feito manualmente.
Acontece que o que interessa numa rede não é o sistema onde ela roda, mas o fato do sistema oferecer uma padronização das interfaces de conversa e da forma de exibição das informações de forma que todos consigam ter o mesmo sistema de organização dos dados. Conseguir ler as informações que alguém posta e conseguir interagir com elas é um critério mínimo para que as pessoas conversem sobre o que lhes interessa.
No entanto, muitas possibilidades de remixagem desses dados, produção de novos usos que sequer ainda pensamos quais seriam ficam travadas no acesso aos dados. Nem falo aqui tanto de usos "gerenciais", mas de usos que sirvam para aproximar pessoas, de formas de nos encontrarmos, de encontrarmos ideias que nos fazem sentido e de conseguirmos organizar/encontrar conversas que mais fazem sentido. Na real, reduzir um pouco a entropia, aumentando a caordem dos fluxos.
Tem bastante gente interessante trabalhando com a tal da websemântica. Alguns textos interessantes dão uma ideia do potencial que isso tem.
A questão-chave que vejo nisso: acontece que numa web com dados mais estruturados, não precisamos mais de sistemas de gerenciamento de conteúdo. A própria web seria isso. Não preciso mais de apis para qualquer tipo de rede social, quando os protocolos que compartilham recursos na web são interoperáveis e conversam com qualquer tipo de servidor. Posso ler os dados, as conversas, encontrar pessoas, descobrir grupos, publicar ideias, articular projetos, enfim, tudo isso, em tese, sem a necessidade de um sistema de informação formal para tal.
Parece utopia, né? Parece uma coisa meio complexa e abstrata demais! Enfim, acho que ainda estamos engatinhando nessas possibilidades e, de fato, estamos falando de uma visão que muda muito a cultura de como temos pensado a web até agora. O que, de fato, mais me estimula como possibilidade do que necessariamente limita. Sem dúvida, como quase todas as mudanças de visão sobre uma tecnologia, há uma curva de aprendizado, amadurecimento de padrões, novos serviços que são criados e comunidades que descobrem novas maneiras de usar a informação e experimentar possibilidades de relacionamentos que ainda não haviam sido pensadas.
Mas, acho que dá para exercitar um pouco mais isso com base nas pesquisas recentes. O que de fato me motivou a tudo isso foi:
- comecei estudando sistemas de bibliotecas digitais federadas. Em tese, são sistemas de informação que coletam metadados publicados em bibliotecas digitais e formam uma base de metadados centralizada facilitando a pesquisa numa interface única. Sem dúvida, isso tem sérias limitações, pois mantém o servidor atualizado é o gargalo da ideia. No entanto, comecei a estudar o padrão Dublin Core de metadados e o protocolo OAI/PMH que faz a coleta de metadados nas bibliotecas digitais para montar a base integrada.
- entender os padrões de interoperabilidade que isso poderia gerar tem sido o trabalho do momento atual. No entanto, isso tem sérias limitações quando pensamos em relacionamentos de pessoas e não apenas a coleta de metadados de publicações de produção científica.
- logo, fez todo sentido abrir mais as pesquisas, entrar em outros protocolos e ver as questões de como os dados mais estruturados podiam abrir algumas interfaces interessantes e que poderiam facilitar a aproximação de pessoas.
- bem, fui estudar FOAF, xmpp, RDF/XML e por aí vai...
- até bater na seguinte imagem de como a websemantica tá sendo pensada:
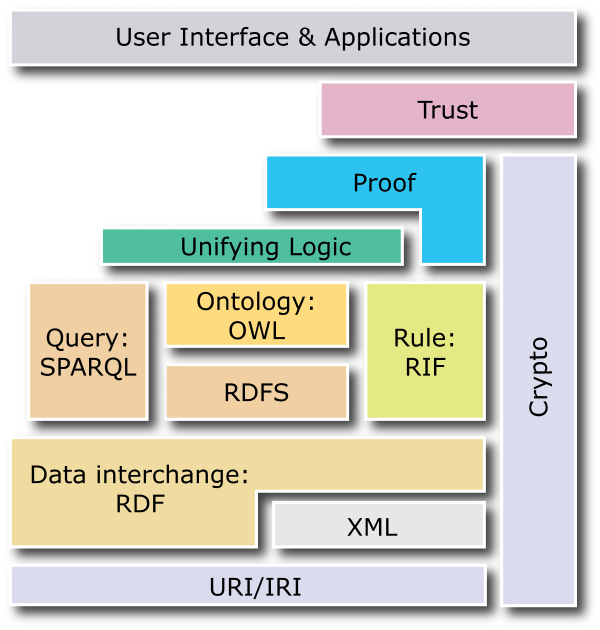
E daí? Qual a vantagem disso?
Vamos imaginar o seguinte:
- eu publico uma URI sobre eu mesmo, contando quem sou eu, o que eu gosto, a quais outros "recursos" estou ligados. Os recursos podem ser projetos, ideias, marcas, universidades, movimentos, outras pessoas, etc, etc, etc..
- o fato de publicar um recurso sobre isso (o que pode ser feito direto em arquivos no meu servidor ou em interfaces entre sistemas de informação, como o Drupal) eu gero toda uma camada de navegação e acesso aos meus dados que permitem várias formas de me encontrar e me remixar. Ex: todo mundo que publicou uma descrição de si dizendo que faz parte da mesma comunidade, que tem interesse nos mesmos tópicos, que trabalha nos mesmos lugares, que usa os mesmos serviços, etc, etc, etc. Infinitos recursos podem ser criados e podem agregar pessoas.
- ao publicar os recursos nos formatos RDF, tudo fica acessível para consulta SPARQL (uma espécie de sql para metadados RDF), permitindo várias possibilidades de cruzamentos de dados. Tudo isso pode ser feito via interface, sem necessidade de digitar uma linha de código. Em tese, novas interfaces de pesquisa e navegação nos dados são possíveis.
- subindo nas camadas, aplicações de conversação podem ser acopladas e se mantém agregadas pelo compartilhamento de URIs. Em tese, os sistemas de informação integrados se dissolvem na rede e os metadados interoperáveis permitem construirmos metasistemas em cima de metasistemas em um número infinito de camadas para além daquilo que podemos imaginar como tecnicamente possível hoje.
vale experimentar?
próximos passos: começar a desenhar um piloto disso! ;-)
Nenhum comentário:
Postar um comentário